什么值得买推荐系统思考
发表时间:2018-03-10 10:42:44作者:zy人气:更新时间:2026-03-11 20:15:13
时逢年假,把自己对部分场景以及推荐系统的理解整理出来,大多只是提出疑问与简单思考。
一、什么才是好的推荐系统
推荐系统要平衡好几方的关系

推荐系统三方关系
用户:接收到有用的、有趣的内容; 站方:在不断的好文推荐中,让用户参与其中,升级消费观念,最终达到转化率效果; 内容提供者:内容的参与度提升,曝光度增加,鼓励用户不断产生内容;
在这三方参与者之间,其实普通用户才是关键。如果用户在阅读过程中,无法接收到有用、有趣的内容,那站方、内容提供者的愿景更是无从实现。什么样的内容才是有用的信息?什么样的推荐系统才是好的推荐系统?从算法角度讲,“精准”是推荐系统的衡量标准,即关联相似度。
可是事实真的是这样吗? 提出几个场景:
用户收藏了一篇关于“家装”内容的文章,就根据相似度理论不断推送同类文章。
一周内用户“好价”内多次搜索、浏览同一关键词,第二周停止搜,用户是不是已经完成购买这一产品了?
用户在好价内搜索“软毛牙刷”,那好文系统应该推送的是“牙刷测评”还是关联”口腔健康“商品的文章呢? ……
推荐系统不仅仅应该只追求“精准”,因为这可能造成两项误区:
重复推送,用户可能已经购买过类似商品或者根本对这类文章失去了兴趣
用户本来就打算购买的商品,单一推荐并不能够增加潜在的消费升级,反而是相似度更小的衍生产品文章,会让用户感到新意,同时提高KOI
所以,对于我们的好文推荐系统体系,要完成的不仅仅应该是“精准”,而是在准确识别预测用户行为的同时,帮助扩展用户的视野,帮助用户发展他们可能感兴趣,自己却并没有发现的内容。
也就是说,好文推荐系统的场景是极为重要的,应该有懂推荐系统和业务流程的产品经理同时加入到推荐系统团队
二、理解用户的行为
分析前,我们首先要关注用户行为和数据:

用户数据来源
以上全部数据都会是判断用户行为的来源。那如果训练一个二进制分类器,首要任务是定义正负样本,为样本定义正负标签绝不是普通任务,联系场景考虑,有什么可能存在的坑?
思路有限,我们就单从好价浏览内容时用户数据入手 先画一个行为漏斗:
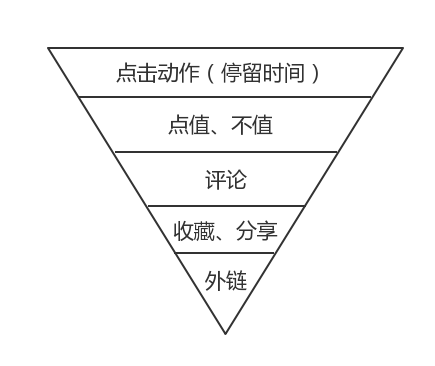
行为漏斗
最简单的思路是:按照行为漏斗的深度对样本行为设立不同权重,判断用户行为偏好,然后进行推荐,可现实场景确实是这样吗?
简单提几个问题: 1、什么样的数据可以看作正样本? 2、点击行为都是正样本吗? 3、点“值”是什么想法?“不值”呢? 4、评论行为证明什么?用户是在提出问题还是回答问题? 5、买过的商品还需要再推送吗? ……
讨论这几个问题的基础要回到推荐系统的第一步:理解/获取用户需求 那用户真的需要什么?怎么理解他的行为?
对刚才的问题一个个来讨论:(不以详尽性为目的,只做讨论)
1、什么样的数据可以看作正样本?
行为漏斗中只有“收藏、分享”这两个动作能被完全看作为正样本,分享的行为成本还要高于收藏,但是收藏对于推荐系统识别是有很大帮助的,这证明用户对于这类商品是有兴趣的,有潜在的购买需求,这符合我们推荐的基本场景。
2、点击行为都是正样本吗?
所有的不点击动作都可以看作负样本,但是对于点击动作也应该分情况讨论。比如:

3、点“值”是什么想法?“不值”呢?
交互动作很大一部分发生在“值/不值”上,但是这个行为是一个很复杂的动作,例如:
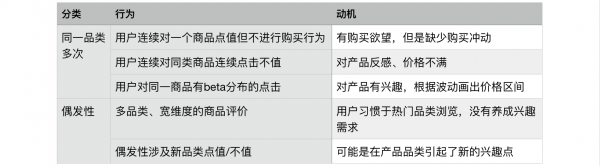
不同频次的“点值/不值”动作,很值得我们讨论。因为点值行为是值得买平台内中为数不多的评分反馈,更可能反应了用户深层次的行为驱动,他真的想要什么?喜欢什么?行为永远比言语更能反应用户的内心。
4、评论行为证明什么?用户是在提出问题还是回答问题?
之前的讨论里用数据分析过评论区中的内容,但是我们分析的是:用户在讨论什么?需要什么?而今天我们除了这个结果以外,我们还需要讨论一点:这些用户是谁?提问者?回答者?他是不是已经购买过这个商品了?我们应该更偏向对于提问者推送相关内容,因为他们是更潜在的购买者, 对于专家用户,可能他已经对类似内容失去兴趣了。
5、买过的商品还需要再推送吗?
不能够确定值得买平台有没有用户购买数据(例如海淘网站返利成功数据),如果存在这个数据库的话,这完全能够用户是否购买过这个产品。如果没有的话,只能从用户深层的行为来判断他是不是购买过这个产品了。
三、推荐场景思考
当理解用户行为之后,开始推荐系统第二步:满足用户需求,用算法做推荐。
大部分电商网站现在都采取了较为成熟完善的协同过滤算法,作为推荐系统的主体。同时也采用了多种推荐系统算法加权累加,例如:FFM、SVM、LFM等。我个人建议以CF item based为主,一是因为算法成熟,便于实现,二是user 数目远大于 item 数目,user based 很难以对用户进行归类。
做相似度分析第一步:Item画像设计,其遵循的原则为提炼出那些易于区分不同Item的显著性特征或标签。这一步需要做详尽性分析,不做讨论。
转而思考计算相似度时, 除了在本身item标签内容中计算相似距离,我们还需要考虑什么场景?什么特殊因子?
1、冷启动场景:
通常在新用户进入系统时,没有数据来源导致冷启动问题,大多数网站采取主动选择标签功能,进行标签相关内容推送:

2、推荐不是“推送”,不同用户的首页流推荐
首页的好文推荐是产品引流最重要的窗口,可是过度推送好文会影响部分产品用户的用户体验,从而影响转化率。如果根据不同用户使用场景决定首页流中好文的推送条数,可能效果会好一些。例如用户停留时间和用户日均浏览数来作为不同参数,确定权重W ,计算评分R
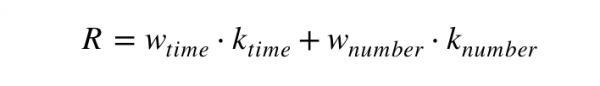
根据评分 R 的不同,来确定首页流的推荐数目。
3、多次重复推送同一品类文章:多样性问题
用户在内容平台所希望收获的文章一定是多样的,如果在较长时间跨度里推荐系统只能覆盖单一兴趣点,那这个推荐列表在长期评估时一定是无法让用户满意的。
那也就是说,我们在推荐系数时,必要考虑一个因子来控制多样性问题,如果当系统想推荐文章i时,我们就要对已经在文章列表R(u)内任意文章 j ,计算相似度,引入

如果系统的推荐分布频次,可以和用户点击频次挂钩,那结果就完全符合多样性要求了。
4、热门内容更热,冷门内容依然无人问津:马太效应
马太效应在UGC平台是常见的,通常体现在用户浏览参与集中于的热门文章中,大部分内容的参与度极低,也可以称为覆盖率问题。覆盖率可以描述一个推荐系统对于文章推荐效果长尾能力的发掘,指推荐文章占全部内容的占比,可以用信息熵度量。
作为整个UGC平台的管理方,站方有责任让所有优质的UGC内容受到关注,而并非只有热门内容,只有克服马太效应,这样才能够让发帖用户感受到更多的关注度,鼓励激发更多的优质内容。
加入一个因子惩罚热门权重
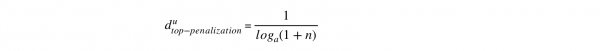
5、产品链层次因素
回想在本文开篇处提出的问题:用户在好价内搜索“软毛牙刷”,那好文系统应该推送的是“牙刷测评”还是关联”口腔健康“商品的文章呢?
宏观来看,所有品类的商品都存在产品链上下层的关系。买了iPhone X的人可能对于手机壳感兴趣,想买普通牙刷的人可能就是漱口水、电动牙刷的潜在消费者。没有一项产品是单独存在的,既然我们要做的是提高用户消费观念,那推荐系统是不是该偏向推送更深层次的内容,加大权重。
6、买过的产品还要推送吗?
当我们已知用户购买过产品后,我们是否应该再次推送相关内容呢? 这个时候我们需要判断商品的消耗性、周期性、以及是否高话题性。这都关乎着是否再次推送内容,什么时候再推送内容。但是具体情况太多,就不做算法推导了。
说一个很有趣的现象,淘宝的推荐系统工程师做过实验,点击率最高的推荐项目是用户刚刚搜过,刚刚完成购买的商品。但是重复推送内容,这是一个好的推荐系统该做的吗?团队目的到底是什么:推荐系统点击率高?提供用户感兴趣的内容?KPI ?不同目的可能导致结果相差万千。
7、实时性
实时性主要是要求推荐系统在分钟级/秒级完成数据分析,作出预判,并且对其作出操作。这个问题主要面对的是技术性问题,因为许多网站的推荐系统都是以天为单位进行日志读取操作,再完成推荐动作。而如果要完成实时操作,就只能简化推荐系统算法,例如 对于User-Item行为矩阵进行扩充动作简化预测过程。
需要根据场景采纳不同的推荐模式,好文内容可能更适合离线式方法。
后记
其实基于值得买推荐系统,XgBoost 与Factorization Machine (最新的FFM)都可能有不错的效果,但是本文讨论以场景为出发点,不讨论算法具体内容,而且业界大多数都认可一个观点,即在推荐系统中:UI > 数据 > 算法,如果让用户接纳,并觉得懂得其心,这才是最关键的一点。












网友评论